0 序言
自从去年学了编译原理已经过去快一年了,之前的编译知识体系的构建太松散,所以我准备重新梳理一遍编译的知识脉络,但我的能力毕竟有限,非常希望有能力的读者能指正我文章中的一些不足之处,编程之道,编译之路也才刚刚起步,能力有限之处也请大家多包涵。
本系列文章阅读前置条件
- 熟悉常见的Grammar定义(Reference里有bnf、ebnf的grammar guide,不熟悉的朋友可以去看看)
1 目录
本系列旨在学习各种parser思路及技巧,分为以下几个部分
- 清晨入古寺—-论世间parser为何物[本篇]
- 初日照高林—-初探First集,Follow集
- 曲径通幽处—-预测分析表的构建
- 禅房花木深—-实现LL(1) parser
- 山光悦鸟性—-递归下降的两种实现
- 潭影空人心—-浅谈recursive ascent parser(SLR,LALR(1))
- 万籁此俱寂—-parser combinator(从ohm.js源码说起)
- 但余钟磬音—-反思与总结
2 论世间parser为何物
以下为王垠前辈原文的科普,Reference会提及建议大家读一读,说起来自己入了PL的坑还是看垠神的博客开始的。
首先来科普一下。所谓parser,一般是指把某种格式的文本(字符串)转换成某种数据结构的过程。最常见的parser,是把程序文本转换成编译器内部的一种叫做“抽象语法树”(AST)的数据结构。也有简单一些的parser,用于处理CSV,JSON,XML之类的格式。
举个例子,一个处理算数表达式的parser,可以把“1+2”这样的,含有1,+,2三个字符的字符串,转换成一个对象(object)。这个对象就像new BinaryExpression(ADD, new Number(1), new Number(2))这样的Java构造函数调用生成出来的那样。
之所以需要做这种从字符串到数据结构的转换,是因为编译器是无法直接操作“1+2”这样的字符串的。实际上,代码的本质根本就不是字符串,它本来就是一个具有复杂拓扑的数据结构,就像电路一样。“1+2”这个字符串只是对这种数据结构的一种“编码”,就像ZIP或者JPEG只是对它们压缩的数据的编码一样。
这种编码可以方便你把代码存到磁盘上,方便你用文本编辑器来修改它们,然而你必须知道,文本并不是代码本身。所以从磁盘读取了文本之后,你必须先“解码”,才能方便地操作代码的数据结构。比如,如果上面的Java代码生成的AST节点叫node,你就可以用node.operator来访问ADD,用node.left来访问1,node.right来访问2。这是很方便的。
对于程序语言,这种解码的动作就叫做parsing,用于解码的那段代码就叫做parser。
3 为什么需要parser
正如上文中王垠说的,程序的运行其实是在不同的数据结构之间做转换,写过Web application的同学肯定对JSON,XML这类数据格式很熟悉,那么传输过程中经常涉及到将系统中的某种数据结构parser到某种传输格式上,包括很多时候从I/O中提取数据也是个parser的过程,只不过这些parser确实比较简单,但确实是日常生活工作中不可或缺的部分,而在编译过程中其实parser就体现了将程序从高人类可读性(比如字符串)转换成高机器可读性(AST)(这里的高机器可读和VMtranslator,汇编器,指令集没有直接关系,只是为了描述高度结构化的AST可以使代码生成更加容易,也就是编译过程友好),而没有parser就意味着手写AST这个过程对于大部分人来说并不是那么直观,不过这确实对于Lisp家族程序员是一件非常美妙的事情,S-Expression万岁~
4 如何使用parser
- 定义好一组文法(CFG等)
- 构建好预测表并选择对应能够解析该文法的算法(LL(1)等)【可选】(可以使用yacc,Bison等解析)
- 将输入数据读入paser【可选】(可以手写tokenizer,也可以使用Lex生成)
此时得到了另一种数据结构,在编译中往往是结构化的AST,当然也可以是XML或者JSON,接下来就是应用这种数据结构的事了。
5 parser图解
由ohm.js生成的AST结构,将1+2*3映射到AST,便于大家感性理解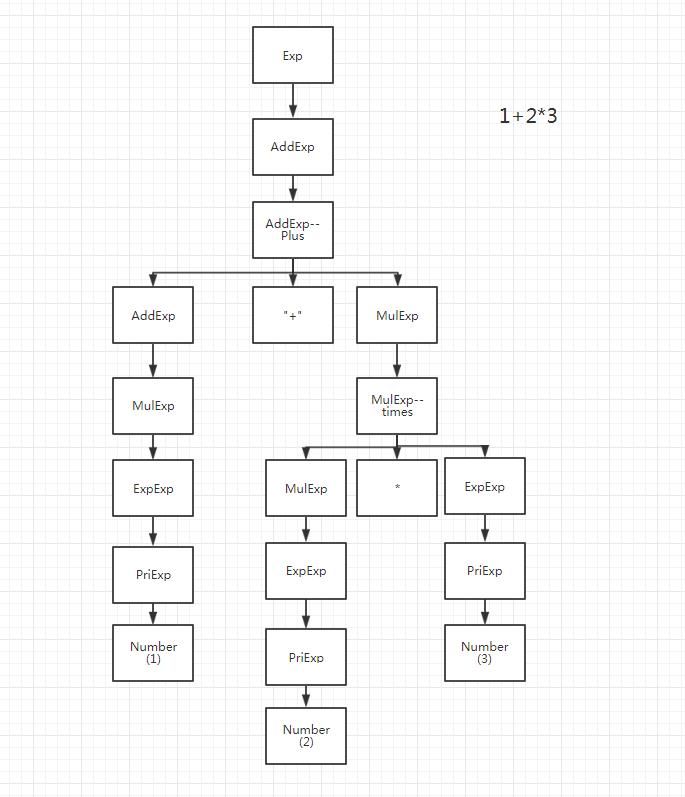
6 Reference
ohm.js
What-exactly-does-parsing-mean-in-programming
王垠前辈—-对parser的误解
Grammar